Internships e Tesi
Unisciti al nostro team e fai la differenza!
Siamo un'azienda di software specializzata nelle energie rinnovabili e attualmente stiamo cercando persone talentuose: se sei appassionato di creare soluzioni innovative per un futuro sostenibile, unisciti al nostro team.
Attualmente Disponibili:

Creazione e automazione di un ambiente di Test
Obiettivi principali
- Progettare un ambiente di test automatizzato basato su tecnologie di containerizzazione (Docker).
- Implementare un sistema di backup e ripristino del database per garantire consistenza tra le sessioni di test.
- Automatizzare il processo di test tramite scripting e strumenti di automazione per verificare sia la RIA che il database.
- Integrare l’ambiente di test nella pipeline di compilazione per garantire esecuzioni rapide, sicure e continue.
Scopi del progetto
- Creare un ambiente di test veloce, sicuro e completamente automatizzato.
- Ottimizzare il processo di verifica della RIA, riducendo errori manuali e tempi di esecuzione.
- Fornire uno strumento efficace per supportare lo sviluppo continuo e l’integrazione di nuove funzionalità.
Competenze richieste
- Conoscenza di Docker e tecnologie di containerizzazione.
- Esperienza con scripting e strumenti di automazione.
- Familiarità con i concetti di pipeline di compilazione e integrazione continua (CI/CD).
- Familiarità con Python.
Lo sviluppo di questa tesi può prevedere rimborsi spese, a seconda delle
competenze del candidato.
Lo sviluppo è previsto presso la nostra sede per circa l'80% del tempo di tesi/tirocinio.

Sistema di previsione della produzione eolica con rete neurale
Obiettivi principali
- Sviluppare e addestrare una rete neurale utilizzando dataset specifici sulle previsioni eoliche e i relativi dati di produzione.
- Implementare una funzione per la generazione delle previsioni di produzione a partire da input meteo forniti in tempo reale.
- Integrare il sistema di previsione nei nostri attuali sistemi di produzione per garantire interoperabilità e utilizzo operativo.
- Obiettivo opzionale: Creare una libreria o interfaccia richiamabile da PHP per consentire l'integrazione con altre piattaforme software.
Scopi del progetto
- Migliorare l’accuratezza delle previsioni di produzione energetica eolica.
- Ottimizzare la gestione operativa degli impianti attraverso strumenti di previsione avanzati.
- Sviluppare competenze pratiche nell’implementazione di algoritmi di machine learning e nella loro integrazione con sistemi software esistenti.
Requisiti
- Conoscenza del linguaggio C#
- Conoscenza delle basi di dati
- Conoscenza del linguaggio PHP
- Conoscenza base dei linguaggi js/php/html/css
Lo sviluppo di questa tesi può prevedere rimborsi spese, a seconda delle
competenze del candidato.
Lo sviluppo è previsto presso la nostra sede per circa l'80% del tempo di tesi/tirocinio.
- Migliorare l’accuratezza delle previsioni di produzione energetica eolica.
- Ottimizzare la gestione operativa degli impianti attraverso strumenti di previsione avanzati.
- Sviluppare competenze pratiche nell’implementazione di algoritmi di machine learning e nella loro integrazione con sistemi software esistenti.
Requisiti
- Conoscenza del linguaggio C#
- Conoscenza delle basi di dati
- Conoscenza del linguaggio PHP
- Conoscenza base dei linguaggi js/php/html/css

Fault prediction: turbina immagine - stabilizzazione su un sistema di produzione
Scopo
- Importare reti neurali python in un aplicativo web
- Generare interfacce di Training utilizzabili dall'utente finale
- Generare API per l'utilizzo delle reti, applicandole in tempo reale
Requisiti
- Conoscenza base di Python
- Conoscenza base del linguaggio C#
- Conoscenza base dei linguaggi js/php/html/css
- Conoscenza delle basi di dati

Condition-Based Maintenance e fotovoltaivo
Scopo
L’algoritmo è stato scelto per essere in grado di svolgere i seguenti compiti
- riconoscere e identificare periodi di scarso rendimento
- riconoscere e identificare tendenze di performance
- rilevamento di anomalie
- legare i punti (1), (2) e (3) a sottosistemi della WTG
I risultati degli obiettivi qui sopra saranno la base per valutare metodi di manutenzione in essere o dare indicazioni di ottimizzazione dei tempi e delle risorse umane ed economiche. In particolare, lo scopo ultimo dell’algoritmo in analisi è di valutare la sua potenzialità per:
- ridurre ulteriormente i costi operativi (OPEX) evitando fermi macchina non previsti e spese di magazzino immobilizzate,
- ottimizzare i ritorni dell’investimento (RoI) collocando gli interventi del personale in periodi con previsioni di bassa produzione
- incrementare l’operatività della macchina migliorando tempo medio tra guasti (MTBF) e tempo medio di riparazione (MTTR).
Requisiti
- Programmazione C#
- Conoscenza base delle reti neurali
- conoscenza delle basi di dati
Lo sviluppo è previsto presso la nostra sede per circa l'80% del tempo di tesi.
Di seguito sono elencate le tesi concluse nel 2024
Previsione di guasto tramite analisi in frequenza
Scopo
- Creare un modello matematico per analisi in frequenza
- Progettare il database in grado di memorizzare tali dati per un asset di 1000+ turbine
- Trovare una metrica di confronto tra risposte di turbine dello stesso modello ad un fronte di vento
- Ipotizzare o implementare sistemi di analisi e previsione dei guasti
Requisiti
- Solide basi matematiche / statistiche
- conoscenza del linguaggio C#
- conoscenza delle basi di dati
Applicazione mobile per parchi eolici
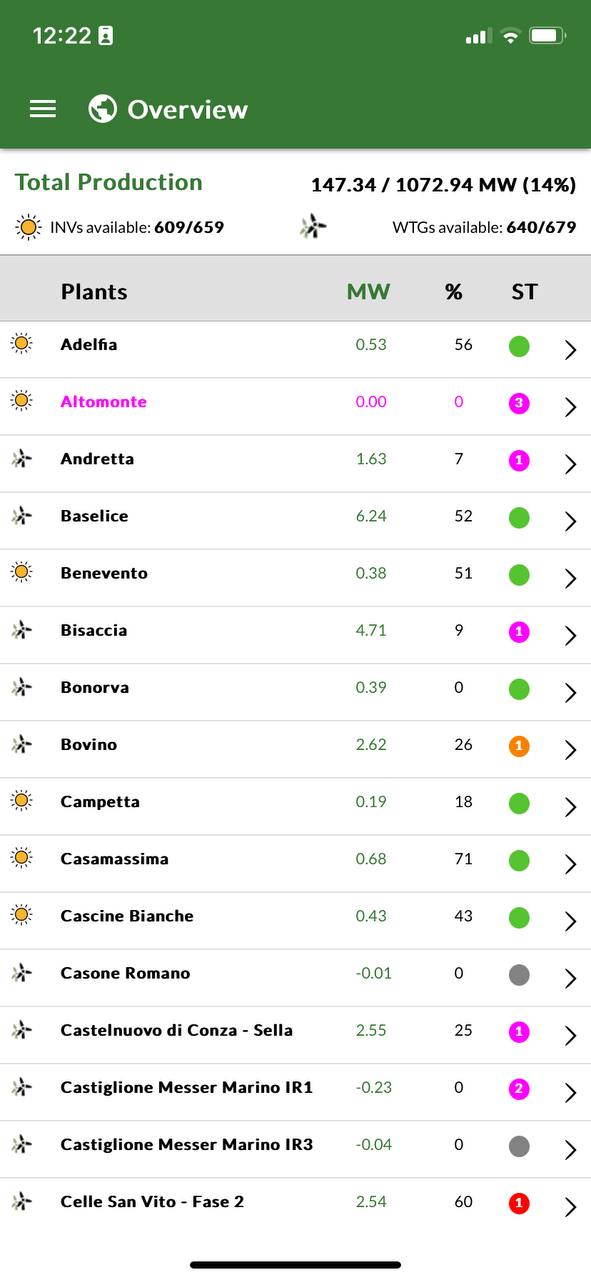
Scopo
- Visualizzare in maniera chiara le principali informazioni di ogni turbina
- Visualizzare in forma compatta le informazioni aggregate di parco
- Utilizzare le sole API standard dei nostri sistemi
Requisiti
- Programmazione JS/CSS/HTML
- Conoscenza delle interfacce grafiche e di tecniche di usabilità
- conoscenza delle basi di dati

Addestramento di un Language Model aziendale per l'ottimizzazione dello sviluppo software e delle procedure aziendali
Scopo
Il contesto aziendale moderno è caratterizzato da una vasta quantità di documentazione tecnica, che spesso risulta dispersa e di difficile accesso. Questa tesi si propone di affrontare questa sfida attraverso l'implementazione di un Language Model aziendale, un approccio avanzato che sfrutta le potenzialità delle reti neurali per analizzare, comprendere e sintetizzare informazioni provenienti da documenti eterogenei.
Si prevede che l'implementazione di un Language Model aziendale possa portare a un miglioramento significativo nelle fasi di sviluppo software e nell'adozione delle procedure aziendali. Ciò dovrebbe tradursi in un aumento dell'efficienza operativa, una riduzione degli errori e un migliore sfruttamento delle risorse disponibili.
Obiettivi della Tesi:
- Addestramento del Language Model: Utilizzare tecniche avanzate di machine learning per addestrare un modello di linguaggio aziendale, impiegando l'intera documentazione aziendale come corpus di addestramento.
- Analisi della Documentazione Aziendale: Estrarre informazioni rilevanti e contestualmente importanti dalla documentazione aziendale, identificando le relazioni tra diversi documenti e contestualizzando le informazioni.
- Sviluppo di un'Interfaccia Intuitiva: Implementare un'interfaccia utente intuitiva che consenta agli sviluppatori di interagire con il Language Model, fornendo assistenza contestuale durante le fasi di sviluppo e implementazione.
- Valutazione delle Prestazioni: Valutare l'efficacia del Language Model attraverso test pratici, valutazioni oggettive e feedback degli utenti, misurando il miglioramento nelle tempistiche di sviluppo e la riduzione degli errori.
Metodologia
La metodologia si basa sull'utilizzo di algoritmi di deep learning per addestrare il Language Model, sfruttando tecniche avanzate di processamento del linguaggio naturale (NLP) per l'analisi della documentazione aziendale. La valutazione delle prestazioni avverrà attraverso benchmarking, confrontando le prestazioni del Language Model con approcci convenzionali.
Requisiti
- Conoscenza delle interfacce grafiche e di tecniche di usabilità
- conoscenza delle basi di dati
Creazione di una Visual Identity aziendale
Scopo
- Creazione di una visual identity legata al mondo delle energie rinnovabili
- Creazione di un filmato della durata stimata di 5 minuti
- Definizione di una grafica aziendale adattabile a video e stampa
- Impostazione di una campagna multipiattaforma
Requisiti
- Conoscenza dei principali motori di editing video
- Conoscenza della programmazione Web (JS/HTML/CSS)
- Conoscenza dei principi base di marketing e strategie di promozione
Sviluppo applicativo per sistemi Embedded
Scopo
- Sviluppare un modello entità relazioni
- Eseguire lo sviluppo di tutto lo stack necessario alla connessione con i dispositivi
- Eseguire i test funzionali
- Integrare quanto sviluppato nel nostro ambiente di test/produzione
Requisiti
- Conoscenza del linguaggio C#
- conoscenza delle basi di dati
Riassunto
Lo scopo di questa tesi è quello di creare un digital twin basato sui dati di un generatore di turbine eoliche in grado di simulare il suo comportamento ideale. Per svolgere questo compito, il modello riceve dati di input sulle variabili ambientali, tra cui la velocità del vento e la temperatura ambiente, e produce valori di output dei parametri che una turbina dovrebbe avere in condizioni ideali, tra cui la potenza prodotta, la velocità del rotore e altro ancora. Il digital twin funge da modello di riferimento che può essere utilizzato come metrica di confronto per le vere turbine al fine di valutarne le prestazioni in tempo reale e verificare che la turbina stia funzionando correttamente confrontando i parametri dei componenti interni.
Il lavoro è stato svolto in collaborazione con l'azienda torinese Sirius s.r.l. e utilizza i dati forniti dall'azienda stessa e raccolti presso alcuni parchi eolici nel sud Italia. I dati sono acquisiti tramite sistemi di Supervisory Control And Data Acquisition (SCADA) installati sulle turbine con l'obiettivo di monitorare e raccogliere dati sia sull'ambiente che sui componenti interni della turbina.
Il lavoro è strutturato in diverse parti: la parte iniziale è caratterizzata dall'estrazione dei dati e dalla creazione del dataset. I dati sono nella forma di una media di dieci minuti e sono prelevati da turbine dello stesso modello appartenenti allo stesso parco eolico. Successivamente, è stato svolto un lavoro significativo sulla filtrazione dei dati con l'obiettivo di mantenere solo i dati relativi ai momenti in cui il comportamento della turbina può essere definito come ideale. In questo modo, gli algoritmi possono essere addestrati solo con dati ideali e possono apprendere adeguatamente le tendenze senza essere ingannati da altri dati non ideali. Per ottenere questo risultato, sono stati utilizzati filtri multipli considerando sia le variabili ambientali che quelle della turbina, utilizzando anche algoritmi come il Density-Based Spatial Clustering of Applications with Noise (DBSCAN) per la rimozione degli outlier. Infine, sono stati creati diversi modelli con i dati filtrati utilizzando diversi algoritmi sia di machine learning che di deep learning, provando molte combinazioni di input e output. In particolare, sono stati testati il Feedforward Neural Network (FNN), il Support Vector Regression (SVR) e il Gated Recurrent Unit (GRU).
I test possono essere suddivisi in due parti: nella prima parte gli algoritmi vengono addestrati su più turbine e testati su altre turbine mai viste in precedenza dall'algoritmo. La seconda parte riguarda invece alcune variabili che rappresentano la temperatura dei componenti interni della turbina, il cui comportamento è altamente variabile da turbina a turbina, anche se appartengono allo stesso modello. In questi casi, sono stati necessari ulteriori studi che hanno portato a soluzioni alternative. In entrambi i casi sono stati ottenuti risultati soddisfacenti.
Riassunto
Tutte le strategie relative alla rilevazione e diagnosi dei guasti dei generatori di turbine eoliche (WTG) possono essere suddivise in approcci model-based e approcci data-driven. Le tecniche model-based si basano principalmente su un modello matematico preciso del WTG e dei suoi sottosistemi. Al contrario, i sistemi data-drivem non richiedono modelli fisici o matematici esatti, ma deducono il sistema di rilevazione dei difetti dai dati osservati dai sensori. Queste ultime tecniche si sono dimostrate particolarmente efficaci negli ultimi anni nella modellazione delle complesse interazioni associate alle turbine eoliche. Tuttavia, la presenza di varie non linearità nei problemi esaminati e il rumore di misurazione richiedono l'adozione di algoritmi complessi e robusti.
Questa tesi propone un framework per la manutenzione data-driven condition-based: l'obiettivo di questo lavoro è sviluppare algoritmi di rilevamento delle anomalie e dei guasti, che possono essere successivamente utilizzati per fornire la manutenzione condition-based. A tal fine, viene fornito un metodo di apprendimento non supervisionato, che coinvolge diversi modelli di reti neurali autoencoder (AE) di tipo feedforward (FNN) o ricorrente (RNN).
Il dataset di questo lavoro è stato fornito da Sirius s.r.l., partner di importanti aziende nel settore delle energie rinnovabili. I dati SCADA, appartenenti a vari parchi eolici situati nel sud Italia, vengono raccolti ogni 10 minuti dalle misurazioni dei sensori meccanici e termici. Il problema considerato include anche diversi design di turbine, con caratteristiche geometriche e meccaniche diverse.
Nel processo, i dati provenienti dai sistemi SCADA vengono acquisiti e raggruppati in base alle prestazioni delle turbine eoliche, facendo affidamento su indicatori chiave delle prestazioni, stati delle turbine e allarmi. Le sequenze temporali con le migliori prestazioni vengono selezionate come input per la successiva fase di addestramento. In modo non supervisionato, diversi modelli AE vengono addestrati in un compito di ricostruzione di serie temporali multivariate. Durante questa fase, i modelli imparano una rappresentazione latente robusta delle caratteristiche chiave della serie temporale. Quando utilizzato su dati non visti in precedenza, l'algoritmo ricostruisce le sequenze di input fornite e l'errore di ricostruzione viene analizzato per la rilevazione delle anomalie.
In questo studio, i diversi modelli di autoencoder saranno quindi esposti a diversi approcci di regolarizzazione, come dropout e de-noise autoencoder (DAE), per valutare la diversa robustezza dei modelli prodotti. Le varie architetture AE vengono quindi testate in un ambiente di benchmark simulato, in cui vengono iniettate anomalie, rumori e comportamenti difettosi al fine di essere rilevati. I modelli più promettenti vengono quindi impiegati in un caso di test nel mondo reale, in cui devono essere rilevati eventi critici delle WTG precedentemente etichettati. L'obiettivo dell'analisi non sarà solo quello di rilevare eventi avversi, ma anche di identificare correttamente le misure e i sottosistemi implicati nelle anomalie.
Questo studio ha dimostrato l'efficacia dei modelli data-driven e alimentati dall'intelligenza artificiale per ottenere valutazioni sull'esistenza e sulla natura delle anomalie. Inoltre, l'efficacia del metodo consente una valutazione delle prestazioni dei parchi eolici e dei loro sottosistemi.
Stiamo cercando persone talentuose e motivate per unirsi al nostro team. Se sei interessato a questa opportunità, ti preghiamo di inviare il tuo curriculum al nostro dipartimento HR. Valuteremo la tua candidatura e ti contatteremo a breve!